ML Paper Notes: Unsupervised Domain Adaptation by Backpropagation
Posted on 2020-06-26Recently, I have been reading a lot of machine learning papers and thought I would start sharing my notes to (1) back up my notes (2) share my digestion of these papers which might help other people understand. Please refer to the actual paper for details as I only sketch the main ideas here.
Title: Unsupervised Domain Adaptation by Backpropagation (2015), Ganin et al.
Main Ideas:
If we want to train a classifier, we would usually need a lot of labelled data. Sometimes, we have a lot of data in our target domain; however, they’re unlabelled. In this scenario, we can try to find another (source) domain where there are a lot of labeled data, then find a way to map the source data and target data so that the network thinks they’re similar - by doing this, we can tap into the large pool of labelled data in the source domain. The mapping can be done manually, but in this paper, the author incorporates the mapping into the neural network itself and the mapping is done automatically via backpropagation. This results in a novel neural network called domain adaptation neural network (DANN). The approach works on any feed-forward neural networks and can be easily implemented with DL packages.
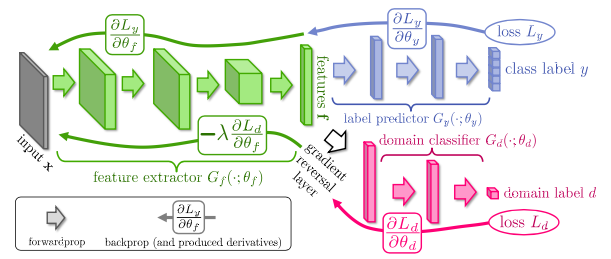
The figure illustrates the three important parts of DANN with three different colors.
- Green (feature extractor Gf): during the feedforward process, input x is mapped to feature vector f, with parameter θf.
- Blue (label predictor): using the feature vector f, Gy classifies the input. In other words, Gy maps feature vector f to a class label with parameter θy. This is the “regular” part of the network that we’re used to seeing.
- Red (domain classifier): using feature vector f, Gd tries to guess whether the input is real (from the target domain) or fake (from the source domain).
The key idea is that we want to map input from both target domain and source domain to similar feature f, so that when the classification Gy is given an unlabelled input from the target domain, it knows how to make a classification, because to it, it has been trained on the same distribution (even though it has only trained on the source domain’s labelled data in disguise).
How do we make sure that target data and source data map to similar f ?
That’s the job of the domain classifier Gd, who when given feature vector f, tries to tell whether the f is mapped from a target data or source data. It acts as an adversarial network that helps train the Gf. The idea is very similar to GAN. Gf is the generator - it tries to map inputs from the source domain in a way such that Gd thinks it’s from the target domain. In other words, Gf’s objective is to maximize the loss of Gd.
Formally, the objective function is
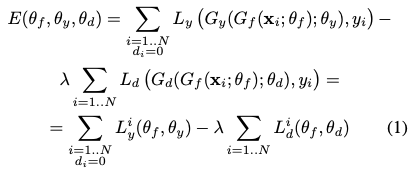
Where what you’re trying to do is
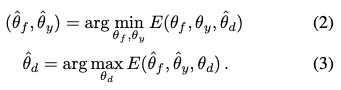
We first look at (2). The first term of E is just the loss of the label predictor Gy. This is no different from any vanilla classification network; therefore, we want to adjust θy so that Ly is minimum. No surprises here. Now look at the second term of E. We want to adjust θf so that Gd can’t tell the different between the two domains (maximize the Ld), and because of the negative sign, maximizing Ld is equivalent to minimizing E.
Now we look at (3). To create the adversary, we must also try to minimize the loss of Gd (improve the discriminator); therefore, we want to minimize Ld (equivalent to maximizing E).
Training then just involves straightforward gradient descent:
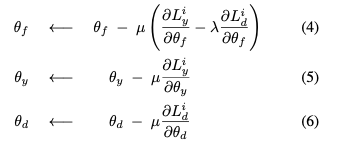
The gradient reversal layer serves to flip the sign during the backpropagation to ensure compatibility with off-the-shelf DL packages.
General Experiment Setup:
During training, each batch is composed of half source data (labelled), half target data (unlabelled). The labelled source data will both train the label predictor Gy and domain classifier Gd whereas the unlabelled source data will only train Gd (because they don’t have labels, they can’t train Gy).
Result of 4 experiments (excluding Office dataset experiment):
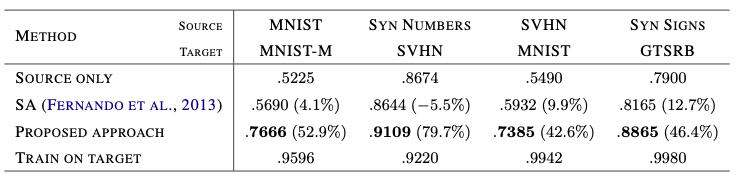
As can be seen, DANN improves the state-of-the-art in domain adaptation method drastically, although the performance is still not too close to training on labeled target-only data.
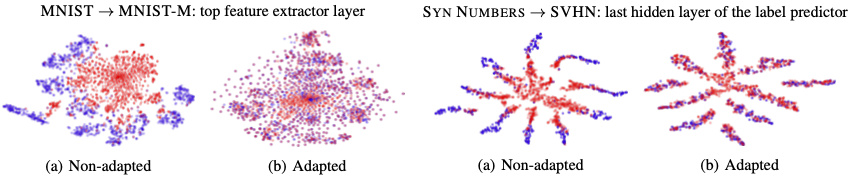
Visualization with t-SNE, an algorithm that casts data onto two dimensions for visualization.
The paper also conducts experiments on the Office dataset and the result outperforms state-of-the-art on all tasks (Amazon -> Webcam, DSLR -> Webcam, Webcam -> DSLR).
Other Notes:
There’s a theoretical discussion on H∆H-distance which I skipped for now.