ML Paper Notes: Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
Posted on 2020-06-30Recently, I have been reading a lot of machine learning papers and thought I would start sharing my notes to (1) back up my notes (2) share my digestion of these papers which might help other people understand. Please refer to the actual paper for details as I only sketch the main ideas here.
Title: Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks (2016) Bengio et al.
Main Ideas:
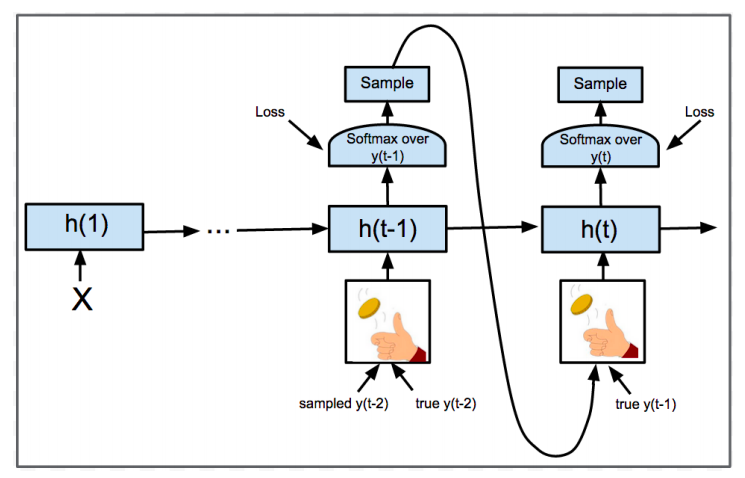
For language generation, the inference and training of RNN have a discrepancy. During training, at each step, you will take (1) an input word (previous target word) and (2) activation from the previous state and make a guess about the next word. Then the next word (answer) is un-covered and you get that word as your input in next step. But if you’re doing text generation, during the text generation, there’s no answer to un-cover, you have to make do with the most likely word in the softmax of the previous step (greedy search) - the inference is a much harder task than the training. This can be mitigated by beam search but the number of possible sequences considered are still severely limited.
The paper seeks to bridge this discrepancy with an approach called curriculum learning, changing the training process to force the model to deal with its mistakes - it makes the training harder so that the model does better during inference time.
Here’s the approach (shown in the figure above): at each step, there’s only a probability p that the input word you receive is the actual word; there’s 1-p chance that you have to make do with the best guess from the previous step as the input word. Note that the loss function is still the same (we still compare the actual word with the previous guess to compute the loss), but it becomes harder to predict the next word correctly — e.g. At step 2, instead of using the actual word (word2) as the input, you use the best guess of step1 as the input. This makes the model less likely to guess word3 correctly. Training thus becomes harder but much more similar to inference - results show that this significantly improves the final model! This makes intuitive sense because human learning works the same way; making the learning harder generally allows students to score better on exams.
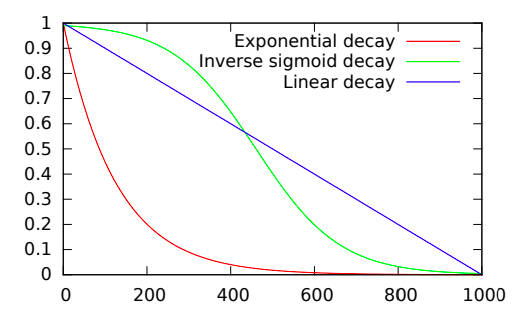
You can use curriculum learning, set p to 1 at the beginning (exactly like traditional training), gradually decrease it to 0 (make the problems harder further down the training). As shown in the figure below, various decay schemes are available for experimentation. While it's a bad idea to use 0 at beginning (it makes the task too hard), some forms of decay almost always make the final model work better.
General Experiment Setup:
- Image Captioning task trained on MSCOCO dataset. Won the competition.
- Constituency parsing
- Speech recognition (slightly different training approach than the paper)
Other Notes:
Seems like this has become a standard technique incorporated into the training of any language model tasks now.