ML Paper Notes: Progressive Neural Networks
Posted on 2020-07-01Recently, I have been reading a lot of machine learning papers and thought I would start sharing my notes to (1) back up my notes (2) share my digestion of these papers which might help other people understand. Please refer to the actual paper for details as I only sketch the main ideas here.
Title: Progressive Neural Networks (2016) Rusu et al.
Main Ideas:
The novel progressive network proposed in the paper is a more generalizable way to do transfer learning than the traditional pre-trained model + fine-tuning method.
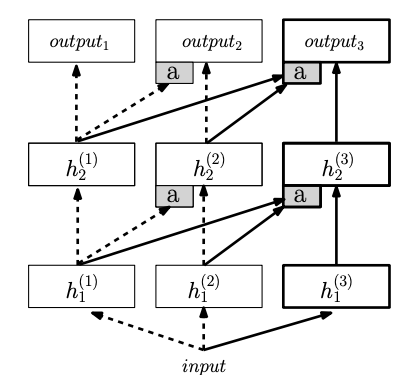
The figure above shows the architecture. Each column is a neural network. To do transfer learning on a new task, you first load a pre-trained model (column 1) with all of the layers frozen. You instantiate the model for the new task as a new column (column 2), with lateral learnable connection to the pre-trained model -- this way, when you fine-tune the model 2 for the target task, it will decide exactly what to learn from column 1. If after learning the first task, you want to learn a new task, you can instantiate a new model (column 3) which lateral connection to the previous 2 models, thereby transferring knowledge from the first two models.
This way of transfer learning is more generalizable than pretrained model + fine-tuning method because (1) the pretrained model + fine-tuning method makes assumption that the two domains are similar (i.e. knowledge in the source domain will help the target task); however, this assumption doesn’t always hold (i.e. sometimes knowledge in the source domain doesn’t help or would even hurt the target task). ProgNet is robust to this because the lateral connection will allow the new task to take whatever it needs from the source model. (2) There’s no catastrophic forgetting because the source model is always in the big model (decision-making process) via lateral connections. And unlike the pretrained model + fine-tuning method, you can learn multiple tasks. This enables continual / lifelong learning.
Note that the linear lateral connection (activation from previous models multiplied by a weight) is sometimes replaced by a single hidden layer neural network. This is called the adapter.
The downside of ProgNet is that you’re adding parameters with the lateral connections - this can get expensive if your network is large or you have a lot of tasks.
General Experiment Setup:
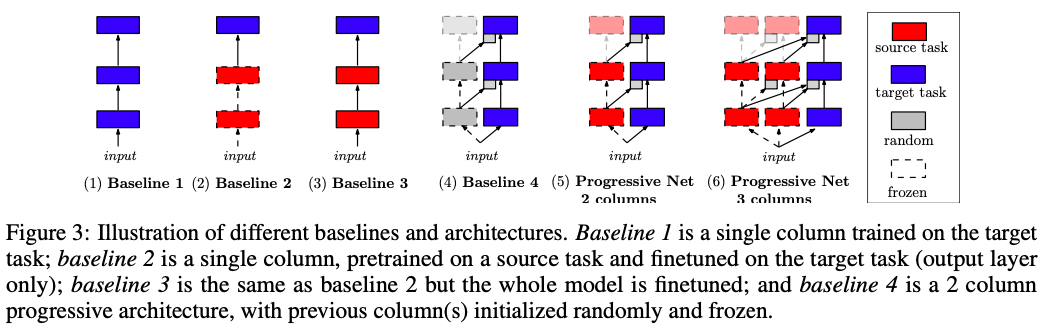
The figure above illustrates all the baselines. Experiments were performed on Pong Soup, Atari Games and Labyrinth. Experiments were tried on up to 4 columns, where you keep adding new source domains (train models on different games before training on the target game) for the target model to learn from. Generally, adding columns increases the performance - the model is able to achieve a higher score in much fewer steps. Especially on more difficult games, ProgNets far outperform baseline 3 (fine-tuning the entire pre-trained model).
(Research) Questions
How many columns can we add to ProgNet before the performance goes down or it gets prohibitively expensive to train the lateral connection weights?
Can we apply ProgNets to NLP?
Other Notes:
Need to learn more about reinforcement to be able to examine the experiments more in detail