BERT: A Detailed Guide to Clear Up All Your Confusions
Posted on 2021-01-17Pre-requisites
- Understanding of Transformer, especially how masking works. (I strongly recommend Jay Alammar's article The Illustrated Transformer and if you're still confused about masking, read my article here.)
- This guide alone will give you a general idea of how BERT works, but it should be more useful to you if you read to the original paper either alongside or after the guide.
What is BERT?
Bidrectional Encoder Representation from Transformers (BERT) is a transformer-based model. It is designed such that it’s easy to train a general-purpose pre-trained model, on top of which you would then attach an output layer to fine-tune for your specific downstream task.
It is important to note that words like “pre-trained BERT model” can be super confusing because the word “model” in ML can be used to refer to two things:
(1) the model architecture (e.g. CNN, RNN, Transformer)
(2) one particular instance of the model, trained on a particular set of data (e.g. WMT, Wikipedia datasets) with a particular set of parameters and hyperparameters.
In the original paper, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2019) Devlin et al, they introduced the "BERT model” in both senses. They first introduced BERT the model architecture (which is great for training models that are meant to be used as pre-trained models in the transfer learning context), then they went on to train a huge BERT model using the BookCorpus (800M words) and English Wikipedia (2,500M words) dataset. By attaching an output layer to this huge pre-trained BERT model and then fine-tuning, they were able to achieve SOTA results on 11 different NLP tasks.
Google has open-sourced BERT model in both sense of the word too. If you go to the repo, you will see that it contains both the code for the BERT model architecture and pre-trained checkpoints from the paper.
Why is BERT a big deal?
BERT the architecture
- It is designed specifically for training models to be used as pre-trained models - good news for transfer learning, which is extremely important for building practical ML applications
- It is unsupervised - the data we can feed to it is abundant!
- It is bidirectional - it can understand the context and therefore perform much better on different NLP tasks
BERT the pre-trained model released by Google
- In the words of the paper, leveraging the pre-trained BERT model, “anyone in the world can train their own state-of-the-art question answering system (or a variety of other models) in about 30 minutes on a single Cloud TPU, or in a few hours using a single GPU.”
- At the risk of academic sloppiness, I like to think of BERT as this young creature that we train to understand a language in general and then we can teach it to do a variety of tasks with just a little further special training.
How does BERT work?
First, BERT really just uses the Encoder portion of the Transformer.
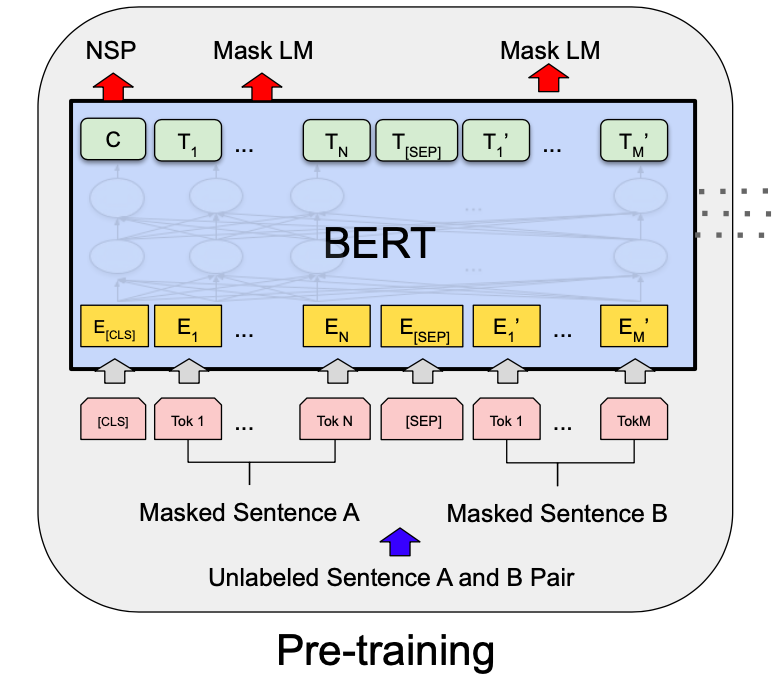
To (pre-)train a BERT model, we go through two steps:
- MLM
- Next sentence prediction
MLM
Bidirectional Conditioning Before BERT
Before BERT, language model training can only be done uni-directionally. It was not possible to train Transformer bi-directionally because "bidirectional conditioning would allow each word to indirectly 'see itself', and the model could trivially predict the target word in a multi-layered context". In other words, masking would not be effective at all if you train bidirectionally.
(If you're interested in exactly why this is, see the Appendix for a detailed walkthrough, but if you just choose to believe the paper's authors, let's move on.)
So how does BERT solve this problem?
Bidirectional Conditioning with BERT
Instead of putting masking in the attention layer by assigning 0 weight/attention to the value vector (recall the Transformer essentially just replace each input token with a weighted average of the value vector of each token in the sentence), BERT puts the masking in the input layer. This makes it impossible for the Transformer to see the masked token - even the input is masked!
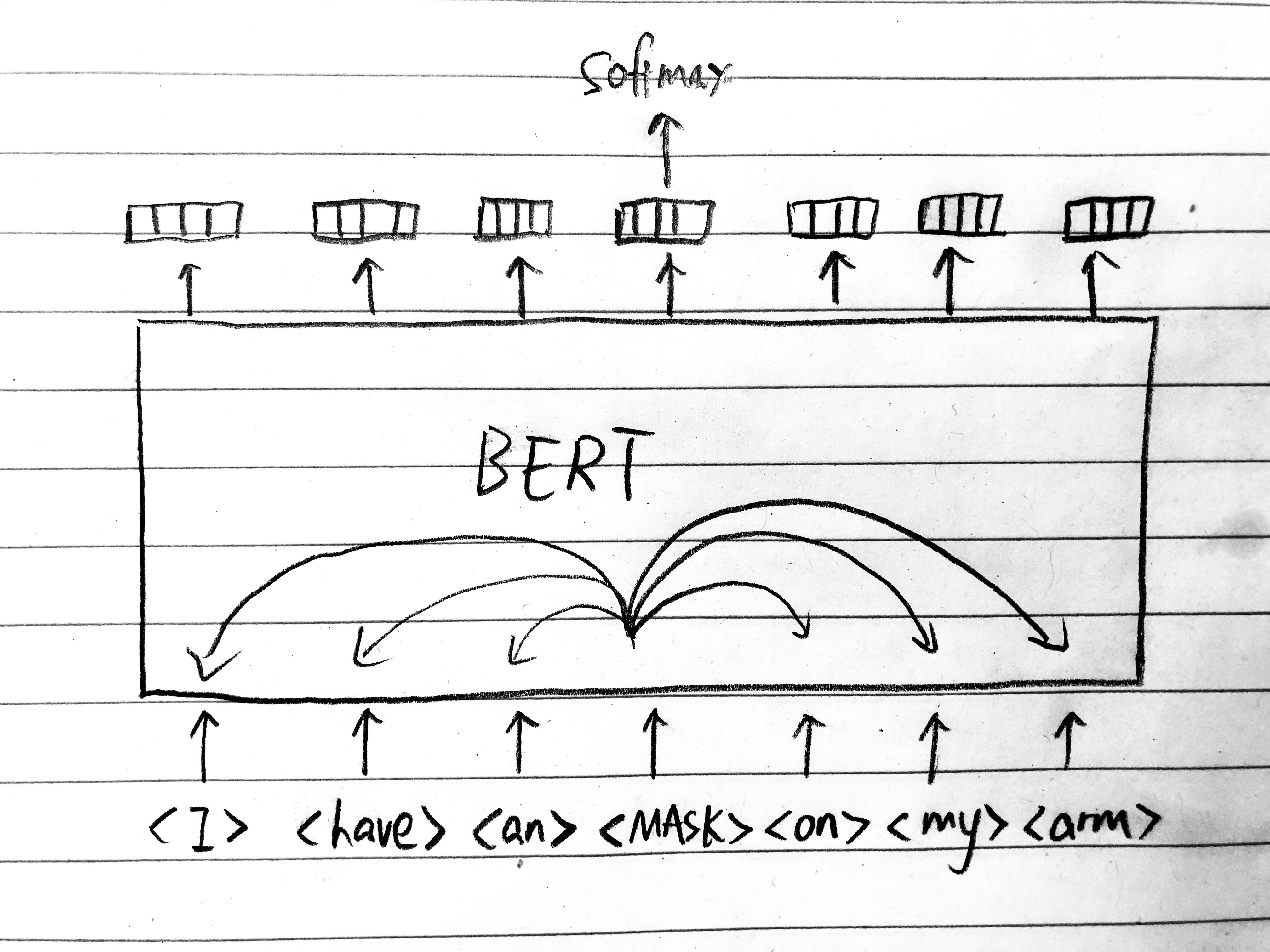
Here's how exactly the masking is done, according to the paper:
"If the i-th token is chosen, we replace the i-th token with
(1) the <MASK> token 80% of the time
(2) a random token 10% of the time
(3) the unchanged i-th token 10% of the time. "
Here's my intuition on why the masking is done this way:
Masking method (1) is a very effective mask technique on its own. Imagine if you train a young child who is just learning to speak this way (i.e. cover a word in the middle of the sentence and have he or she guess what the covered word is), the child would probably get very good at guessing over time and in the process, gain a much better sense of the English language in general.
However, we're dealing with machines here. If we only had (1), we would have a mismatch between pre-training and fine-tuning, because during fine-tuning we would never get a <MASK> token as the input in any NLP task. Therefore, we need masking method (2) and (3) to mimic the real dataset.
Intuitively, (2) and (3) make up another word game where you're pointing to a word and have the machine guess whether that word is supposed to be there based on the context. If it is, it should predict the identity; if not, it should give its best guess. Let's say the real sentence is "I have an ant on my arm" and the fourth token is chosen to be masked.
Method (2) would give: <I><have><an><gone><on><my><arm>
Method (3) would give: <I><have><an><ant><on><my><arm>
The machine would either see the sentence given by method (2) or (3), but it doesn't know which one! That's why it has to try really hard to extract information from the context.
If only method (3) is used, it would be easy; the machine would figure out it can always guess the identity and be correct. That's why we have method (2), the machine knows that it can't just predict the identity - it would have to really look at the surrounding words to decide whether to predict the identity or a different word.
If only method (2) is used, there is still a mismatch between pre-training and fine-tuning, because you may be giving the machine very unlikely sentence as the input. How often do you see "I have a gone on my arm" in a real dataset?
Next Sentence Prediction
While MLM trains BERT to understand intra-sentence relationship, Next Sentence Prediction trains BERT to understand inter-sentence relationship, which is important for downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI).
You have
[Sentence A, sentence B]
50% of the time, sentence B is the actual sentence that follows A. The other 50% of the time, sentence B is just a random sentence from the corpus.
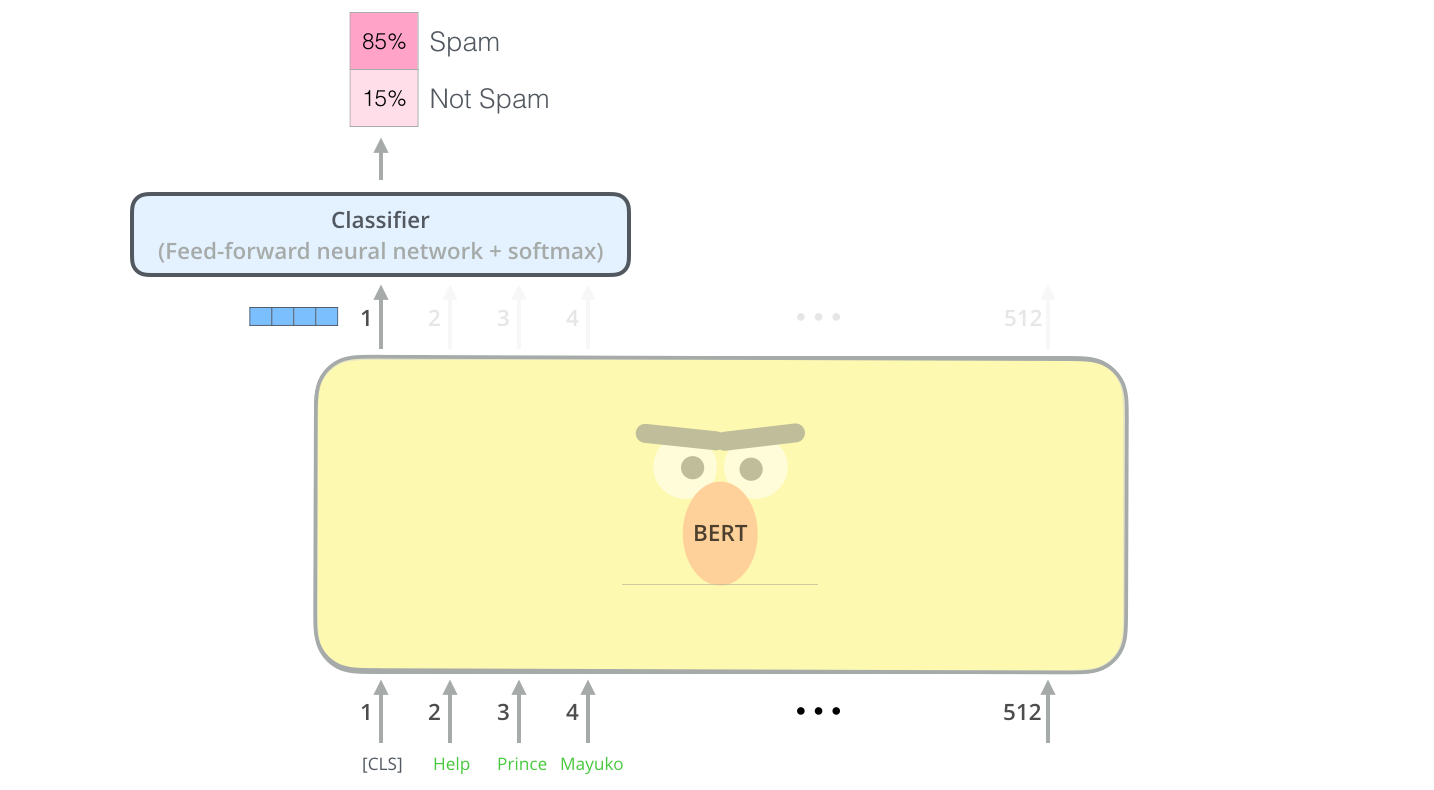
You insert a token <C> at the beginning of sentence pairs, which should map to an embedding, then you attach a logistic regression head to it. The head should output whether isNext is true or false.
Fine-tuning BERT for downstream task
After you pre-train BERT on MLM and Next Sentence Prediction, you should have a model which has a very good sense of the language you're training for. Now, you just need to fine-tune it for your downstream task.
To use a BERT model for your final downstream task, there are two ways:
- Fine-tuning
This is quite self-explanatory. Import a pre-trained BERT model and then fine-tune it end-to-end for your final task. Of course, you would need to swap out the correct inputs and outputs, which you would be looking at quite closely when you're actually training your model, so I won't go into detail here.
- BERT as feature-based approach
In this case, you just feed the outputs of the pre-trained BERT as features into your custom network, similar to how you would use hidden layers of a CNN (lines, edges, shapes etc.) as input features for computer vision tasks.
So that's the general idea of BERT! There are of course many details in the implementation but these should answer a lot of your confusions. If I got some details wrong, feel free to email me below!
Appendix
"Bidirectional conditioning would allow each word to in- directly 'see itself', and the model could trivially predict the target word in a multi-layered context".
Why exactly?
The key is in "multi-layer context".
Let's consider training a language model bidirectionally with a Transformer. Recall that the a masked Transformer encoder layer is like a set function where given n input tokens, it would replace each of the n tokens with the weighted average of all the tokens before it, thus outputting n embeddings.
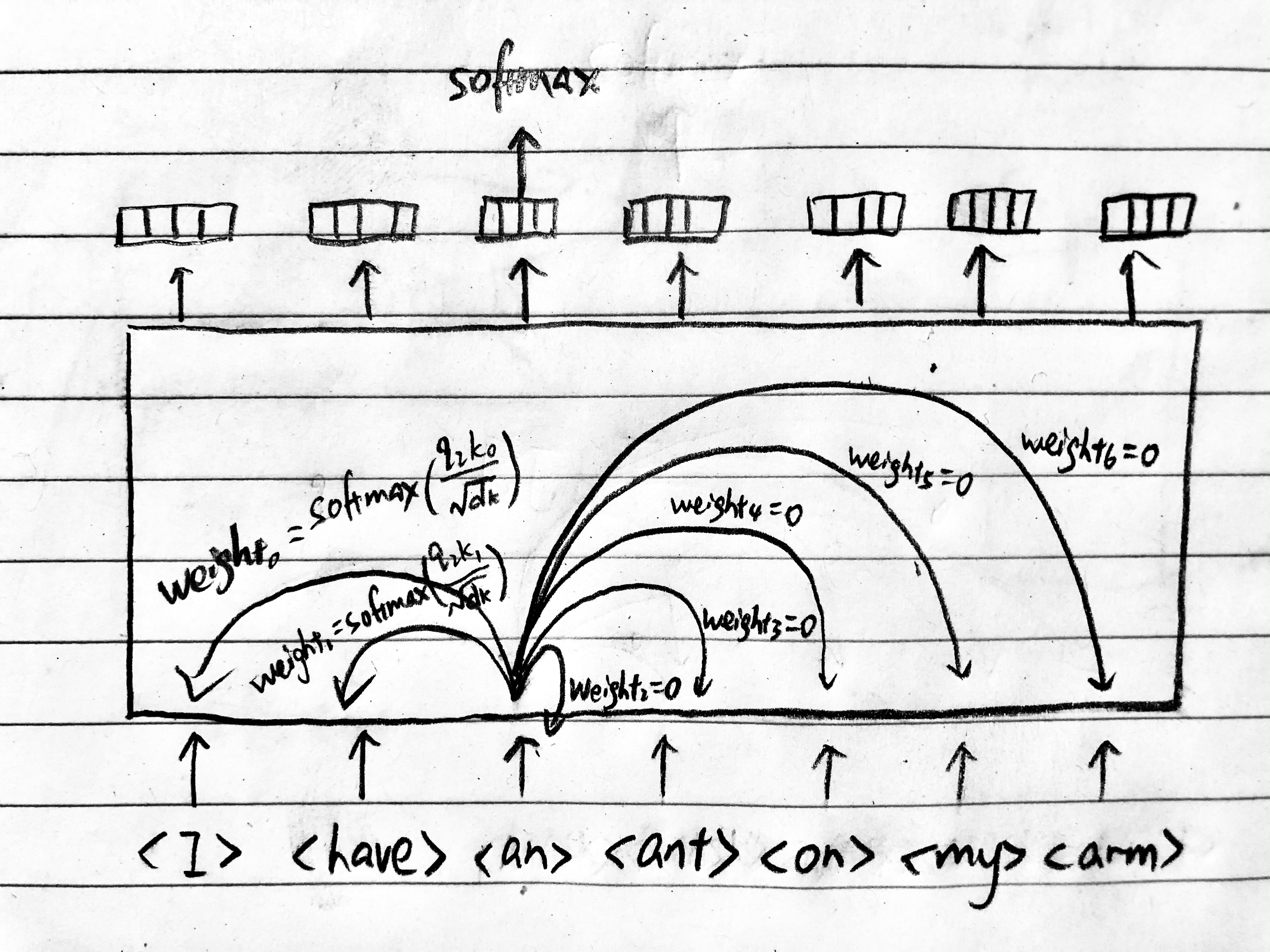
Now, during bidirectional conditioning, you would first do a forward pass from left to right, where at token t, you would mask all the tokens from t rightward until the end of the sentence and thereby assigning zero weight/attention to them. In the illustration below, the w_t represents how much weight/attention we assign to the token; the absence of arrows means 0 weight. In this example, we're given <I>, <have>, <an> and asked to predict the word that comes next, which would be given by the output of <ant>; note though that <ant> cannot see itself because of masking - the output of <ant> would assign 0 weight to itself.

Then you would do a backward pass, during which at token t, you would mask all the words from t and leftward. Given <on>, <my>, <arm>, you're asked to predict the word before, which is also given by the output of <ant> -- <ant> still can't see itself because its weight/attention is zero due to masking.

You will then either add or concatenate the forward pass and backward pass output for <ant> and use that for the next layer.
So far so good. <ant> doesn't seem to see itself during the forward pass or the backward pass, so how can it see itself??? That's why I said that the word "multi-layer" is important!
Recall that Transformer trains all the tokens parallel-ly. So even though <ant> cannot see itself, <on> can see <ant> during the forward pass. So the output of <on> after the first layer contains information about <ant> (specifically, it contains <ant>'s value vector), and all <ant> has to do, in order to indirectly "see" itself, is, in the next layer, pay special attention to the output of <on> during the backward pass. Now, <on> is not the only token that can see <ant> - every token rightward of <ant> can! So it should be pretty evident that the network can easily learn to enable each token to "see" itself and predict identity during bidirectional conditioning with the traditional masking heuristic.