Masking in the Transformer Explained
Posted on 2020-10-03The Transformer is a landmark breakthrough in NLP that is explained quite well by Jay Alammar's article The Illustrated Transformer. This article is about masking, a very specific component of the Transformer that I was extremely confused about when I was first learning it.
To understand what masking is, it is necessary to understand why masking is necessary in the Transformer by tracing back to the earlier concepts in sequence models.
Perhaps the best way to understand the Transformer (as presented in the original Attention is All You Need paper) is to compare and contrast it with the RNN encoder decoder, which is essentially a conditional language model.
A conditional language model behaves slightly differently during the two stages of its lifecycle: training and inference.
During inference (after the model has been trained), the conditional language model (encoder decoder) takes an English sentence as an input, feed it through the encoder to generate an encoded vector (called hidden state), which will serve as the initial activation of the decoder network (In a sense, the decoder is like a vanilla language model whose initial activation a0 is the encoder's output). Receiving the hidden state vector and the < bos > (beginning of sentence) token, the decoder will predicts its first softmax vector (what it thinks the French word might be at that step, assigning the highest probability to the word it thinks is most likely, which in this case is "bonjour"), then "bonjour" is fed into the next step alongside with the activation (assuming we're taking the greedy decoding approach as opposed to beam search), until the < eos > (end of sentence) token is predicted, by which point the French sentence translation would have been generated. Notice the prediction at each step depends on the previously predicted words.
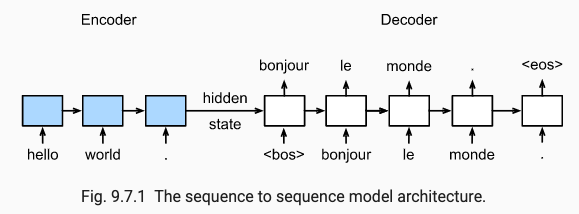
The network behaves slightly differently in the training stage (which caused much of my confusion when I was first learning it): During inference, the network is given an English sentence and asked to generated the French translation. During training, the network is also given an English sentence and asked to generate the French translation, except that during the decoding (translation), the decoder has access to the answer - the training examples are sentence pairs of < English sentence, French translation >. This difference is important.
Let's say the training sentence pair is < "hello world", "bonjour le monde" >. Our decoder, after reading the hidden state vector generated from the encoder which reads "hello world", predicts a softmax vector that gives the highest probability to "au revoir", which differs from the actual translation of "bonjour". The next step in the recurrence will not use "au revoir" (predicted previous word) as its input at all; instead it will use "bonjour" (actual previous word). The network inputs the actual previous word instead of the predicted previous word into the next step because recall that now (at the training stage), the network has access to the answer (the actual words).
If you think about it, each step of the decoder doesn't really know anything about the softmax predictions made in the steps before it (even though those predictions are compared to the actual words to compute the loss for backpropagation)1; it only knows what the actual word is before it. Try to convince yourself that this is true, as this insight was what made it all click for me.
OK, enough review. Enter the Transformer.
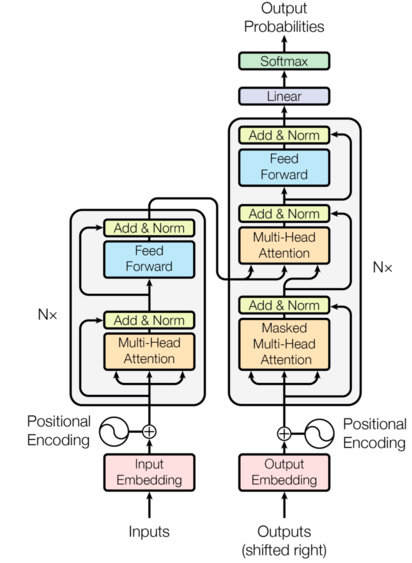
I won't go into much detail here but the Transformer can be thought of a set function, where it takes an input English sentence and for each word in the sentence, replaces the word vector with a weighted average of every word in the sentence (depending on the relative attention that word should pay to each of the other words in the sentence) as the output, and it does so in parallel. This is an important improvement over RNN for two reasons:
(1) Every word can attend to every other word in the sentence directly instead of indirectly as in the case of RNNs (or bidirectional RNNs).
(2) The parallel computation replaces recurrence, which was costing a huge amount of training time and computational power.
Wait, but what is masking and why do we need it again?
OK, so similar to RNN, during the decoding phase of the Transformer, at each step, we want the network to take a look at the actual French words previous to that step and output a softmax prediction for what it thinks the next word is. In RNN, the network does this sequentially, word by word, it looks at "le" and the activation accumulated from all of the previous French words, in order to output the softmax prediction. However, the Transformer attends to every word in the sentence, before and after, so here at the 3rd step, it will see the entire sentence: "bonjour", "le", "monde". It becomes trivial for the network to predict the next word - it will simply learn to put 100% attention to the word after it. But this is cheating, it won't learn anything really, because during inference, it won't have the answer (the entire French sentence) available to it and it'll be useless.
This is why we need to apply masking2 - we don't want each word in the decoder to see the words that come after it. The way we do that is by setting the attention paid to the subsequent words to 0. The paper describes this as setting the scaled dot-product attention to −∞, which essentially makes the attention weight (a softmax vector) 0, because e^(−∞) = 0.
Thus, masking helps prevent the decoder from cheating by paying all of the attention to the immediate next word and allow the Transformer's full advantages to take effect!
Footnotes
- Note that this changes a bit when you're using scheduled sampling, where you use a mix of actual previous words and predicted previous words during training. My guess is that you can't directly apply scheduled sampling to Transformers because scheduled sampling relies on some words being predicted earlier than others (in order to use them as the input) but Transformers compute the predictions for every word in a sentence in parallel.
- Masking is only applied to the decoder, not the encoder.